

With the rapid expansion of the digital landscape, the web has evolved into a central hub for exchanging vast amounts of data. However, this growth comes with rising concerns-unauthorized data collection and exploitation through web scraping and crawling. Although scraping and crawling are commonly used for legitimate purposes like search engine indexing and data accumulation, they are also frequently misused for copyright infringement, personal data leaks, and unauthorized exploitation, leading to service abuse and security risks.
In today’s digital landscape, where web-based services are on the rise, indiscriminate data scraping is more than just a technical challenge-it poses a serious security threat that undermines content protection and user trust.
Unauthorized data replication and leakage don’t just lead to financial losses; they also decrease customer engagement and erode corporate credibility. Cases of unauthorized data scraping are becoming increasingly common, making crawling and scraping prevention a critical priority for content security. Addressing this issue requires a structured approach that integrates both technical protection and legal frameworks to ensure a safer web environment.
As indiscriminate data collection becomes the norm, this post will explore the key characteristics of web crawling and scraping, along with effective prevention strategies. We’ll also examine the limitations of traditional anti-scraping and anti-crawling solutions and discuss how to overcome these challenges.
Web Crawling vs. Web Scraping
While often used interchangeably, web crawling and web scraping serve different purposes in data extraction.

1. Web Crawling : The Process of Exploring Data
Web crawling refers to the process of systematically browsing the web by using automated bots(so-called ‘crawlers’) and collecting information from the web. Since manually extracting vast amounts of online data is practically impossible, crawlers are used to systematically navigate web pages and gather information automatically. Unlike web scraping, which focuses on extracting specific data from a webpage, web crawling is about building an entire system for discovering and collecting information across multiple web pages. Crawlers are commonly used by search engines, such as Google, to index content and help users find relevant information efficiently.
Crawlers visit and navigate through millions of web pages, continuously accessing links and loading pages in an automated cycle. During this process, the crawler bot sends HTTP requests to retrieve the HTML content of a page, extracts the necessary data, and stores it in a database for further processing. This mechanism is primarily used by search engines like Google and Naver, which index web pages to provide relevant search results. When a user searches for a keyword, the search engine’s crawling algorithm enables it to display a list of web pages along with their content, making information more accessible.
* Common Misconception About Web Crawling : We often come across phrases like ‘Stock Market Crawling’, ‘Linked IN Crawling’, or ‘E-commerce Price Crawling’, which suggest methods for extracting data from specific services. However, most of these discussions actually describe web scraping techniques rather than true web crawling. In reality, many of these guides rely on CSS Selectors to extract data from HTML pages, which is a fundamental method of web scraping rather than crawling. These techniques typically involve making one-time HTTP requests to retrieve specific information, lacking the systematic, large-scale data collection that defines true web crawling.
2. Web Scraping : The Process of Extracting Data
Web scraping refers to the process of extracting specific information from a web page and storing it for further use. A scraper sends an HTTP request to load a webpage, analyzes its HTML structure, and extracts targeted data, which is then stored in a database. Unlike web crawling, which systematically explores and collects data on a large scale, web scraping focuses on gathering specific pieces of information from a narrower dataset. For example, scraping can be used to extract specific news articles from a news site or automatically collect stock prices and real estate listings from financial platforms.
3. Similarity Between Web Scraping and Crawling : DOM-Based Data Collection
3. Similarity Between Web Scraping and Crawling : DOM-Based Data Collection Web scraping and crawling are both widely used techniques for data collection, sharing a fundamental approach-leveraging the Document Object Model(DOM) to explore and extract data. The DOM is a structured representation of a webpage, built with HTML, CSS and JavaScript, allowing browsers to render content in a hierarchical manner. Since the DOM provides direct access to a webpage’s elements and data, both scraping and crawling rely on it as their core foundation.
Key Similarities
1.
DOM Structure Analysis : Both web scraping and crawling analyze the DOM to locate and extract relevant data.
2.
Plaintext Data Collection : Both techniques retrieve plaintext data directly from the DOM, making them highly dependent on how information is structured within web pages.
4. Differences Between Web Scraping and Web Crawling : Data Collection Methods
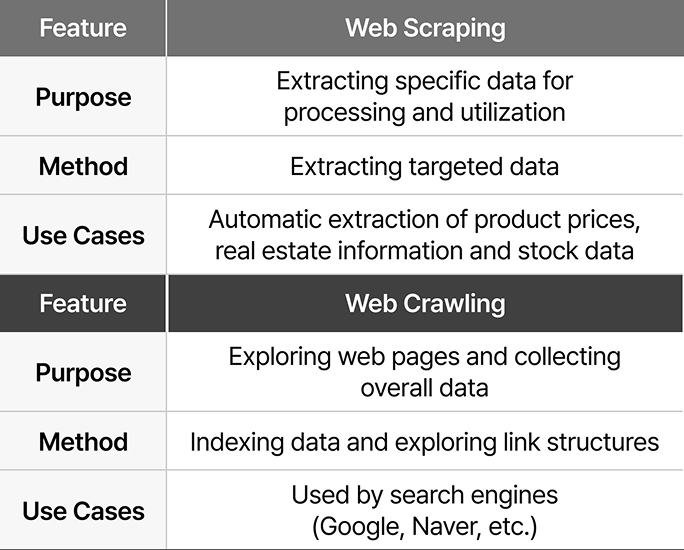
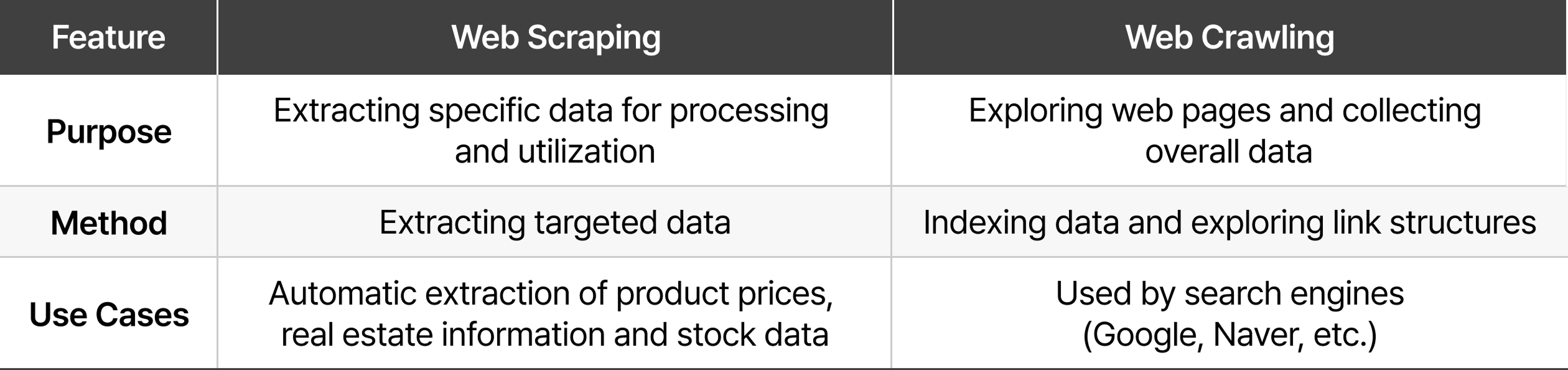
The key difference between web scraping and web crawling lies in their data collection approach. Web scraping and crawling both use automated bots to efficiently collect web data, and the two terms are often used interchangeably. However, they have clear differences in purpose and method.
Web crawling involves following links across websites, analyzing structures and indexing data to build search engines or databases. Its primary focus is on systematically navigating web pages to gather large-scale information. In contrast,web scraping is designed to extract specific data from targeted web pages for analysis and utilization. It is commonly used for collecting product details, pricing information or other structured content. In summary, web crawling is a broad exploration process for large-scale data collection, whereas web scraping is a focused process for extracting precise information.
How to do Web Crawling / Scraping
Web pages can be classified into two types based on how they load content : static web pages and dynamic web pages. A static web page is fully rendered on the server before being sent to the client, meaning all content is delivered at once as a complete document. In contrast, a dynamic web page generates content in real-time on the client side, often relying on JavaScript to fetch and render data dynamically. Because these two types of pages handle content differently, scraping and crawling methods must be adapted accordingly to effectively extract data from each type.

Basics of Web Scraping and Crawling
Both web scraping and crawling operate on a simple principle. Since web pages deliver content through HTML documents, scraping and crawling begin by sending an HTTP request to a server or browser to retrieve an HTML page. Once the HTML document is received, the process involves analyzing the DOM(Document Object Model) to extract relevant data. If the goal is to pull specific pieces of information, it is classified as scraping. On the other hand, if the focus is on structuring and indexing large amounts of data, the process is categorized as crawling.
1. Scraping and Crawling Static Web Pages
Static web pages maintain a pre-rendered HTML structure, meaning their content is fully generated before being sent from the server to the client. Because of this, accessing HTML content is nothing complicated—simply by visiting the URL, the entire page structure could be retrieved. Static scraping/crawling involves loading an HTML page via a URL and extracting relevant data using libraries such as Requests and BeautifulSoup. This process allows the HTML document to be parsed and structured, making it possible to extract text, images, media, and other content efficiently.
2. Scraping and Crawling Dynamic Web Pages
Dynamic web pages are characterized by content that is generated in real-time on the client side. These pages cannot be fully accessed by simply visiting a URL, as the data is dynamically rendered in live-time, making it harder to collect the information directly. Dynamic web pages are often used for sites where data changes continuously, as they help reduce server load.
To handle dynamic scraping/crawling, automated browser libraries like Selenium or Puppeteer are used. These tools simulate user interactions within a web browser, allowing data collection from pages that rely on real-time data generation. These browser automation libraries control browser behavior through low-level drivers, enabling interaction with HTML elements, executing JavaScript, and extracting or collecting page data. Additionally, by analyzing the API calls from a web page through the browser’s developer tools(network tab), you can identify URLs and headers to extract data more efficiently.
The Legal Dilemma : Is Web Scraping and Crawling Legal?
In an era where data is a valuable asset, various tools and technologies are now available, making it easy for anyone to collect web data. The rise of technologies like ChatGPT has made web scraping and crawling more efficient and powerful, enabling anyone to leverage publicly available data. However, indiscriminate scraping and crawling pose significant threats to a company’s data assets.
So, the question arises : Is web scraping and crawling legal or illegal? And can legal measures be implemented to prevent unauthorized data collection? The legality of web scraping and crawling depends on various factors, including the terms of service of the website, the nature of the data being scraped and the manner in which scraping or crawling is conducted. Unauthorized scraping can violate terms of service, lead to copyright infringement or breach privacy laws. Therefore, while scraping publicly available data may seem legal and harmless, restrictions and protections are increasingly coming into focus as the issue grows.

1. Ethical and Legal Considerations in Web Scraping and Crawling
Web scraping and crawling are powerful tools for automatically collecting data, but it is critical to consider ethical and legal issues before implementing them.
Firstly, the purpose of data collection must be legitimate and legal. Data should never be used in malicious or unethical ways. When using collected data for commercial purposes, it is essential to ensure that copyright laws are not violated. Additionally, compliance with the Robots.txt(Robots Exclusion Standard) is a critical requirement. The robots.txt file is a protocol set by website owners to indicate the level of access bots are allowed to have, and it specifies whether crawling is permitted. Therefore, it is important to check a webpage's robots.txt file and comply with the specified rules before proceeding with scraping or crawling.
Despite these ethical and legal considerations, there is no clear legal standard that defines whether scraping and crawling publicly available data is legal or illegal.
2. Case Studies of Web Scraping and Crawling Disputes
Let’s examine the legality of web scraping and crawling through an actual legal dispute.
A recent lawsuit between Company A and the real estate platform Company B highlights the legal complexities of web crawling. Company B crawled property listings posted by Company A and posted them on its own platform, using Company A's data for commercial purposes. In response, Company A filed a lawsuit, claiming that Company B's actions infringed upon its database rights. The domestic court ruled in favor of Company A, determining that Company B had violated Company A's rights as the creator of the database. This case illustrates how web scraping and crawling can potentially infringe upon intellectual property rights, particularly database protection and copyright laws.[1]
On the other hand, some legal precedents have recognized the legality of crawling publicly available information. For instance, in the case between LinkedIn and hiQ in the United States, the act of collecting publicly available profile information was deemed legal, and this case illustrates how data collection from publicly available sources can be allowed in some jurisdictions. This demonstrates that the legality or illegality of data collection can vary depending on the jurisdiction, the specific case, and the interpretation of the law by the judges or legal professionals involved.[2]
As a result, service providers are increasingly focusing on the implementation of security measures against scraping and crawling, rather than relying on legal post-action steps, as the legality of scraping and crawling can be subject to interpretation of local laws and specific circumstances.
Limitations of Existing Web Scraping/Crawling Prevention Measures
To prevent unauthorized scraping and crawling, many companies implement a variety of technical defenses. However, these measures often fall short, as there are methods to bypass them, making it difficult to fully stop unauthorized data collection. Below, we’ll explore some of the key scraping/crawling prevention technologies and their limitations.
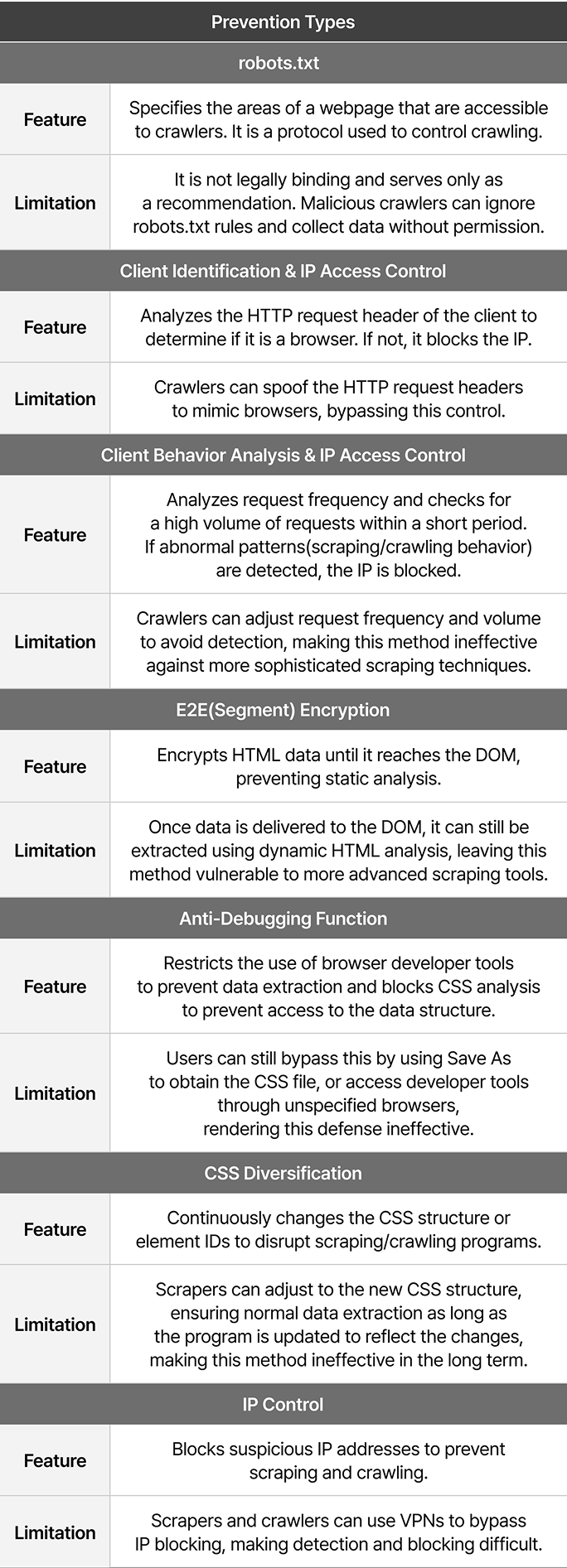

The technologies mentioned above can be superficially effective in preventing web scraping and crawling, but each method has its ownsecurity vulnerabilities that can be easily mitigated. Therefore, to effectively prevent scraping and crawling, a fundamental solution is required.
Zero Trust-Based Web Scraping/Crawling Prevention

While the security measures to prevent web scraping and web crawling utilize various approaches to protect data, each method has its own bypass techniques and vulnerabilities. So, what fundamental measures should be prioritized to prevent web scraping and crawling?
Most existing prevention methods focus on data access control within the web browser, and since bypassing these controls is not overly difficult, it becomes impossible to prevent data extraction once a hacker gains access to the DOM (Document Object Model) of the web browser. Traditional web services have treated web browsers as safe zones, which has led to a focus on securing the end-to-end (E2E) process, from the web server to the browser. However, this approach overlooks the potential for data extraction from within the web browser's internal DOM.
To effectively prevent scraping and crawling, a Zero-Trust principle is required, where every request and interaction with the web browser is continuously verified, regardless of the source or internal environment. This would reinforce security within the browser itself, making it significantly impossible for attackers to access and extract data from the DOM.
Therefore, by adopting a Zero Trust-based security approach, even within the DOM area of the web browser, users should not be trusted to access the data. If the user fails to pass the authentication, the data should remain obfuscated or encrypted. Only after successfully authenticating through a secure process can the data be accessed, and this access should be limited to specific URLs and time periods. Through this method, the data of web-based services can be protected from web scraping and crawling attacks, ensuring a higher level of security.
1. Preventing Web Scraping/Crawling Through DOM Data Obfuscation
To fundamentally prevent web scraping and crawling, protecting the DOM is essential. Due to the nature of web browsers, data within the DOM exists in plaintext, making it easily accessible to scrapers and crawlers who can indiscriminately collect this data. Therefore, data in the DOM should be encrypted and obfuscated to ensure ongoing data security. Additionally, obfuscated data should be unreadable if extracted without proper authorization.
This method applies to both static scraping, where data is directly extracted from HTML, and dynamic crawling, where the DOM structure generated by JavaScript is analyzed. By obfuscating or encrypting the DOM data, both static and dynamic scraping and crawling can be effectively prevented.
2. Preventing Web Scraping/Crawling by Blocking Developer Tools(F12)
Blocking developer tools focuses on preventing scraping and crawling through API and network request information and DOM structure analysis. Traditional browser access controls are often ineffective, as crawlers can easily bypass them by manipulating header information or user-agent strings, which fails to prevent static or dynamic crawling. Therefore, a more robust approach is needed, one that blocks access to developer tools entirely, thus preventing network request analysis and HTML structure analysis.
Additionally, to prevent the use of developer tools on unspecified browsers and operating systems, it's crucial to block access to developer tools across all browsers and OS environments, ensuring that scraping and crawling attempts are thwarted from any platform.
As the digital landscape evolves, web scraping and crawling have emerged as significant security challenges, posing both opportunities for data utilization and threats to data security. While existing web scraping/crawling prevention measures have their merits, they all have security vulnerabilities in access control mechanisms that can be mitigated, meaning they do not fully block scraping and crawling. Ultimately, to protect web systems from scraping and crawling, more fundamental technical measures are necessary.
Therefore, to fundamentally prevent web scraping and crawling, the adoption of a Zero Trust-based web browser protection is critical. This approach involves obfuscating the data within the DOM of the web browser and preventing developer tools access to block network request analysis and HTML structure analysis, effectively preventing scraping and crawling.
Zero Trust-based web security goes beyond just protecting data-it has become a core strategy to securely protect a company's content and data, while maintaining the trustworthiness of the service. Through Web-X DRM, built upon Zero Trust-based scraping/crawling prevention, businesses will be able to strengthen data security in the digital environment and provide a more secure and trustworthy web service.
References :
[1] Son Ji-hye, Electronic Times (South Korea), "Real Estate Crawling Dispute, Naver Wins… Seoul District Court Orders Darwin to Pay Compensation," October 8, 2024. https://www.etnews.com/20241007000224
[2] Kim Yun-hee, ZDNET Korea, "US Court: 'Scraping Public Website Data is Not Illegal'," September 10, 2019. https://zdnet.co.kr/view/?no=20190910101800