

웹 스크래핑(Web Scraping)은 웹페이지에 렌더링된 데이터를 자동으로 수집하는 기술입니다.
최근 다양한 온라인 서비스에서 웹 스크래핑 기술 사용이 크게 늘고 있습니다. 예를 들어, 쇼핑몰 가격을 한 번에 비교해주는 서비스나, 여러 사이트의 뉴스를 자동으로 모아주는 앱, SNS의 인기 게시물을 분석해 ‘요즘 뭐가 뜨는지’ 보여주는 페이지도 모두 같은 원리입니다.
특히 AI 기반 스크래핑 도구가 보편화되면서, 일반 사용자도 웹사이트의 페이지 구조를 분석해 데이터를 추출할 수 있는 환경이 만들어졌습니다.
이번 글에서는 웹 콘텐츠 스크래핑이 어떤 원리로 이루어지는지, 그리고 왜 최근 들어 더욱 흔하게 사용되고 있는지 알아보겠습니다.
웹 스크래핑(Web Scraping) 개념 정리
우리가 매일 이용하는 웹사이트에는 수많은 정보가 담겨 있습니다. 상품 가격, 뉴스 제목, 게시글 내용, 리뷰, 이미지 등 다양한 데이터가 화면에 표시되는데, 이런 정보를 사람이 하나씩 복사·정리하는 대신 자동으로 가져오는 기술을 바로 웹 스크래핑이라고 부르며, 대표적인 웹 데이터 수집 기술입니다.
쉽게 말해, 브라우저에 표시된 다양한 정보를 프로그램이 자동으로 수집해 정리하는 기능입니다.
웹 스크래핑 사용이 증가하는 이유
예전에는 개발 지식이 있어야 자동 수집을 구현할 수 있었지만, 지금은 ChatGPT와 같은 AI 기반 웹 스크래핑 자동화 도구 사용이 쉬워지면서 간단한 문장 입력만으로도 코드가 생성되는 환경이 마련되었습니다.
“이 URL에서 제목과 날짜만 가져와줘.”
“이 쇼핑몰 100페이지를 자동으로 돌면서 가격 정보를 모아줘.”
이런 요청만으로 간단한 웹 스크래핑 스크립트가 자동 생성됩니다.
또한 기업들은 시장 트렌드 분석, 경쟁사 페이지 모니터링, 고객 반응 수집, 데이터 자동 정제 등 반복적인 작업을 효율화하기 위해 대량 정보를 자동으로 가져오는 웹 데이터 수집 기술인 스크래핑이 적극 활용되고 있습니다. 이러한 기술은 인력 투입을 최소화하면서도 필요한 데이터를 빠르고 정확하게 확보할 수 있다는 장점이 있습니다.
웹 스크래핑 작동 원리: 브라우저 렌더링과 DOM 구조
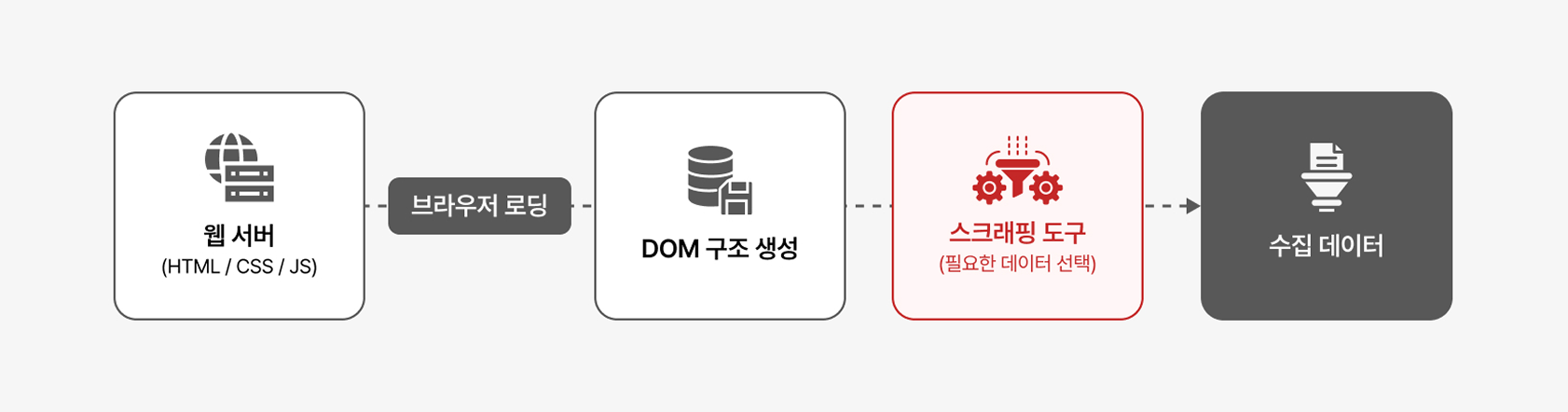
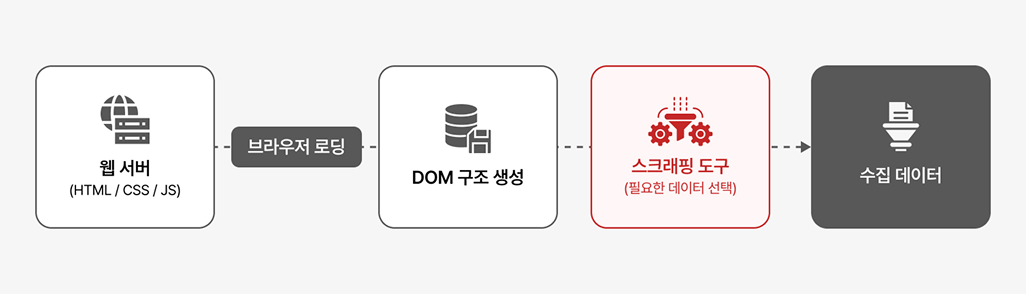
스크래핑을 이해하려면 먼저 웹페이지가 어떻게 화면을 만드는지 간단히 살펴볼 필요가 있습니다. 웹사이트는 단순히 ‘그림’처럼 한 번에 그려지는 것이 아니라, 브라우저가 HTML 코드를 읽고 화면을 구성하기 위한 기본 구조를 먼저 만든 뒤, 그 위에 텍스트·이미지·버튼 같은 요소를 하나씩 올려 최종 화면을 보여주는 방식으로 동작합니다.
이 기본 구조를 전문 용어로는 DOM(Document Object Model)이라고 부르는데, 실제 화면에는 보이지 않지만 웹페이지가 어떤 모양으로 만들어질지 미리 그려둔 ‘보이지 않는 설계도’라고 이해하면 됩니다.
즉, 화면에 보이는 정보는 모두 브라우저 내부에 구조화된 형태로 존재하며, 브라우저 렌더링 이후 DOM에 포함된 데이터가 스크래핑 대상이 됩니다
최근 웹 스크래핑 기술이 더 정교해진 이유
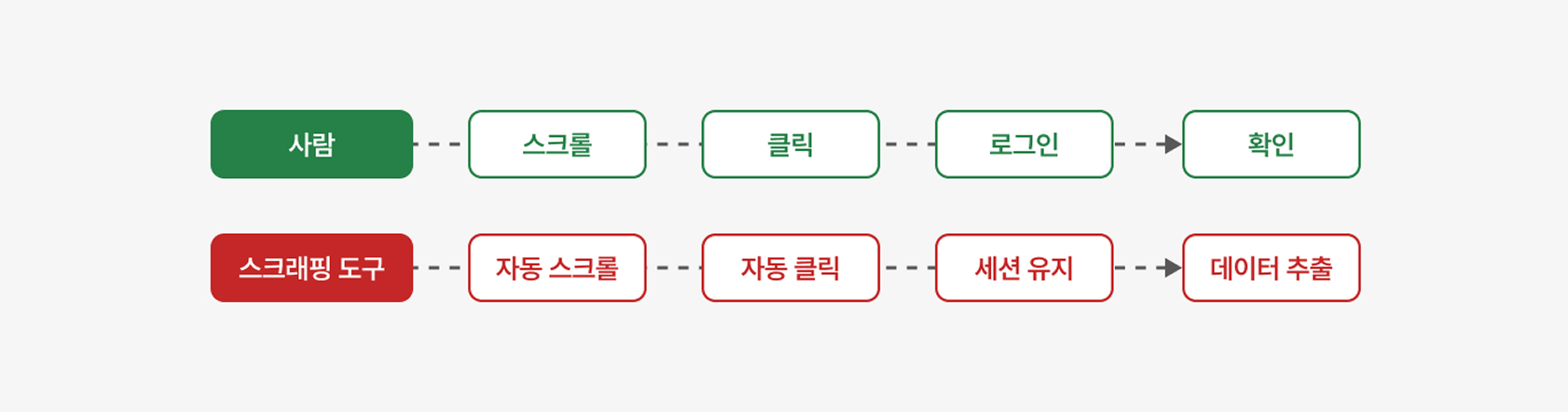
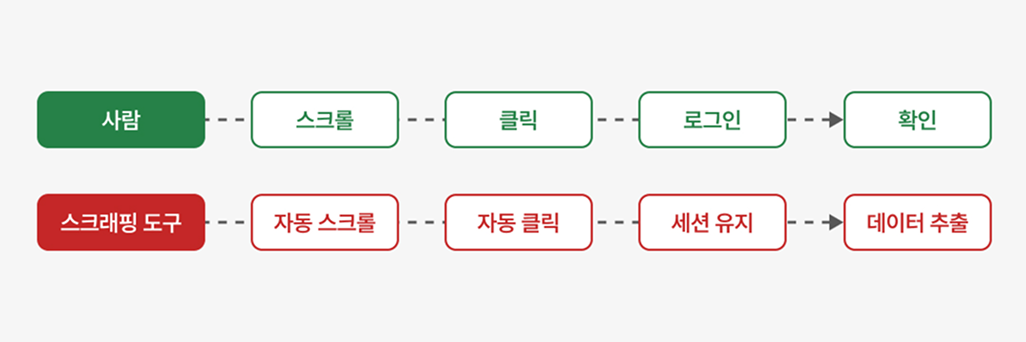
최근 웹사이트는 스크롤을 해야 내용이 보이거나, 버튼을 눌러야 추가 정보가 나타나는 등 동적으로 작동하는 구조가 많아지고 있습니다.이런 변화 때문에 스크래핑 기술도 사람이 실제로 웹사이트를 사용하는 방식처럼 동작하도록 빠르게 발전하고 있습니다.
예전처럼 화면에 보이는 글자만 단순히 가져오는 것이 아니라, 페이지를 실제로 열고 보이지 않는 영역까지 스크롤을 내리고, 필요한 버튼을 눌러 데이터를 모두 불러온 뒤 내용을 읽어가는 방식으로 훨씬 더 정교해진 것이죠. 이 과정에서 아래와 같은 기술들이 활용되면서 스크래핑은 사람이 직접 사용하는 것과 거의 비슷한 수준으로 발전했습니다.
웹 스크래핑에 사용되는 주요 기술들
웹 스크래핑에서 사용되는 주요 기술들은 다음과 같습니다.
헤드리스 브라우저(Headless Browser)
사용자 행동 시뮬레이션
로그인·세션 유지
동적 콘텐츠 로딩 처리
AI 기반 웹 스크래핑 코드 자동 생성
최근에는 이렇게 스크래핑에 필요한 다양한 기술들을 AI가 손쉽게 조합해주기 때문에, 과거에는 전문가만 가능했던 정교한 스크래핑 작업이 이제는 일반 사용자에게까지 빠르게 확산되고 있습니다.
웹 스크래핑 악용 시 발생하는 보안 위험
스크래핑 기술이 발전하면서 긍정적인 활용도 많아졌지만, 반대로 악의적인 목적으로 사용될 경우 웹 스크래핑의 위험성이 크게 드러날 수 있습니다. 대표적인 위험은 다음과 같습니다.
콘텐츠 무단 수집·유출 및 재배포 위험
경쟁사 정보 자동 수집 및 영업 기밀 유출
개인정보 자동 수집 및 프라이버시 침해
대량 요청으로 인한 서버 과부하 및 서비스 장애
웹 스크래핑으로 유출되기 쉬운 분야별 정보
서비스 유형에 따라 스크래핑으로 노출되기 쉬운 정보도 달라집니다. 아래는 웹 스크래핑으로 쉽게 유출될 수 있는 분야별 정보들입니다.
전자상거래(쇼핑몰)
콘텐츠/미디어
교육·LMS 플랫폼
기업·B2B 서비스
웹 스크래핑 기술, 어떻게 바라봐야 할까
스크래핑은 기술 자체가 나쁜 것이 아니라, 어떤 목적으로 사용되느냐에 따라 가치가 달라지는 기술입니다. 단순한 데이터 정리부터 연구·분석까지 넓게 쓰이지만, 동시에 악용될 경우 기업 자산과 이용자 정보가 쉽게 유출될 수 있기 때문에 그 위험성을 반드시 함께 이해해야 합니다.
특히 웹페이지에 ‘표시되는 순간’ 대부분의 정보는 수집 대상이 될 수 있기 때문에, 서비스 제공자 입장에서는 화면 단에서의 보안이 점점 더 중요해지고 있습니다. 기술이 발전한 만큼 이를 안전하게 활용할 수 있는 환경을 구축하는 것 역시 필수적인 과제가 되고 있습니다.